Publications

DATR: Domain Agnostic Text Recognizer
(Accepted)Abstract: Recognizing text extracted from multiple domains is complex and challenging because complexities vary from one domain to another. Most existing methods focus either on natural scene text ... or specific text type but not text of multiple domains, namely, scene, underwater, and drone texts. In addition, the state-of-the-art models ignore the vital cues that exist in multiple instances of the text. This paper presents a new method called the Student-Teacher-Assistant (STA) network, which involves dual CLIP models to exploit cues in multiple text instances. The model that uses ResNet50 in its image encoder is called helper CLIP, while the model that uses ViT in its image encoder is called primary CLIP. The proposed work processes both models simultaneously to extract visual and textual features through image and text encoders. Our work uses cosine similarity for the randomly chosen input image to detect instances similar to the input image. The input and similar instances are supplied to primary and helper CLIPs for visual and textual feature extraction. The outputs of dual CLIPs are fused in a different way through the alignment step for recognizing text accurately, irrespective of domains. To demonstrate the proposed model's significance, experiments are conducted on a set of standard natural scene text datasets (regular and irregular), underwater images, and drone images. The results on three different domains show that the proposed model outperforms the state-of-the-art recognition models.
ICPR, 2024
Code
DITS: A New Domain Independent Text Spotter
(Accepted)Abstract: Text spotting in diverse domains, such as drone-captured images, underwater scenes, and natural scene images, presents unique challenges due to variations in image quality, contrast, text ... appearance, background complexity, and external factors like water surface reflections and weather conditions. While most existing approaches focus on text spotting in natural scene images, we propose a Domain-Independent Text Spotter (DITS) that effectively handles multiple domains. We innovatively combine the Real-ESRGAN image enhancement model with the DeepSolo text spotting model in an end-to-end fashion. The key idea behind our approach is that improving image quality and text-spotting accuracy are complementary goals. Real-ESRGAN enhances image quality, making the text more discernible, while DeepSolo, a state-of-the-art text spotting model, accurately localizes and recognizes text in the enhanced images. We validate the superiority of our proposed model by evaluating it on datasets from drone, underwater, and scene domains (ICDAR 2015, CTW1500, and TotalText). Furthermore, we demonstrate the domain independence of our model through cross-domain validation, where we train on one domain and test on others.
ICPR, 2024
Code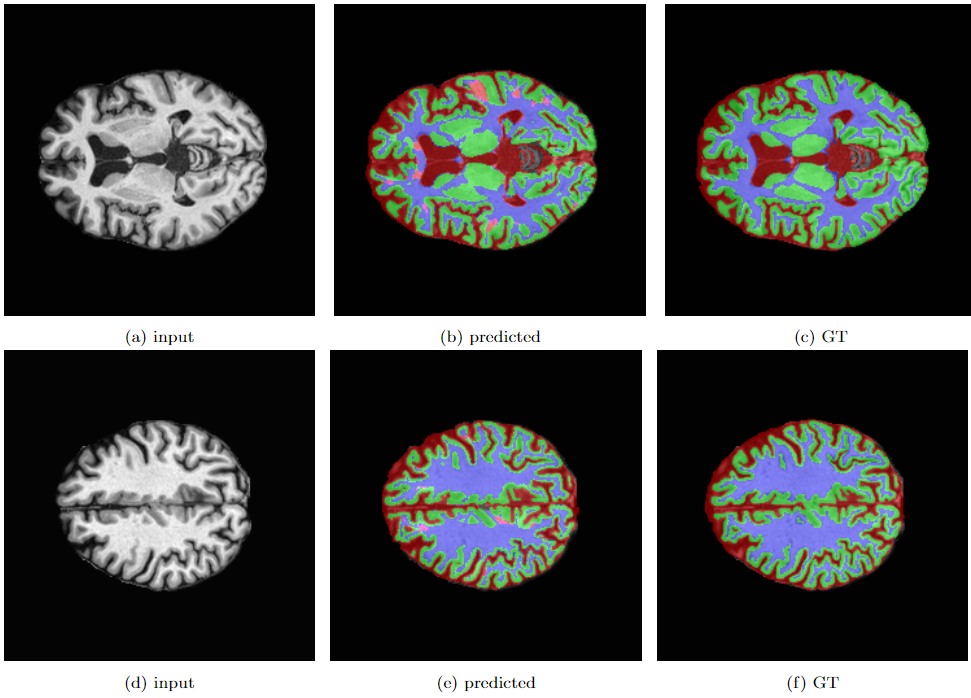
PIRNet:Two-step Deep Neural Network for Segmentation of Brain MRI with Efficient
Loss Functions
(Accepted)
Abstract: Aim: Segmentation of normal and crucial tissues of the brain from the Magnetic Resonance Imaging (MRI) scans is the first and foremost task to conduct during any medical analysis. Until a few years ago, this task was ... performed manually by radiologists regularly and repeatedly which made it tedious and error-prone. In the recent past, Machine Learning-based techniques with varying accuracies and complexities have been explored to address this issue. Inspired by the fresh advancements of deep concatenated neural networks and residual connections in image segmentation, we propose a deep analysis of brain MRI segmentation of cerebrospinal fluid(CSF), gray matter(GM), white matter(WM), and background(BG) over several loss functions. Materials and Methods: In this paper, a state-of-the-art model, Pyramidal Inception Residual Network (PIRNet), based on a novel technique called Pyramid Pooling, together with the combination of inception blocks and residual connections, is proposed for the task of brain MRI segmentation and validated on well-known publicly available datasets namely, MRBrains13, iSeg17, and CANDI. A thorough analysis of deep learning architectures coupled with comprehensive experiments on loss functions such as Tversky loss, label-wise dice loss, categorical cross-entropy loss, and weighted categorical cross-entropy loss, has been performed to uncover the most suitable combination of loss functions to finely tune the segmented results. Results: The suggested model, PIRNet yields $94.55\%$, $91.28\%$, and $91.91\%$ average dice score on the MRBrains13, iSeg17, and CANDI datasets respectively thereby surpassing the performance of all the known modern techniques. Additionally, we have carried out an ablation analysis to investigate the effectiveness of our model. We explore the strengths and weaknesses of each of the architectures along with their interfusion. This paper also demonstrates the usage of various loss functions and their corresponding strengths which further enhances the robustness of the proposed algorithm and the architecture as a whole. Conclusion: The presented method addresses the multifaceted challenges faced in the volumetric segmentation of the brain tissues and can be applied in multiple segmentation problems such as liver lesion segmentation, breast cancer detection, etc. We believe that our approach can be of remarkable significance in quantitative accurate computational modeling where conventional clinical applications require timely interactions.
ASCIS, 2024
Code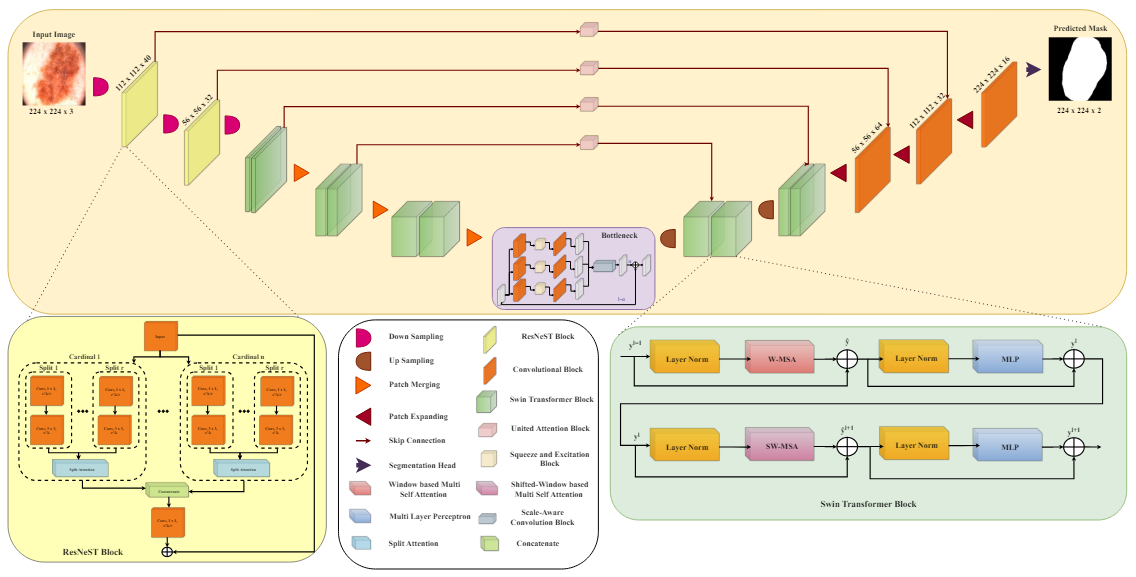
Swin-ResNeST: A CNN-Transformer Based Hybrid Model for Skin Image Lesion
Segmentation
(Accepted)
Abstract: Skin lesion segmentation is a well-studied topic that faces obstacles such as differences in lesion shape, size, and color, varied skin tones, and image noise. ... This study describes a U-shaped architecture designed for skin lesion segmentation. It uses ResNest blocks, Swin Transformer blocks, and Unified Attention methods integrated into skip connections. This CNN-Transformer hybrid model is effective in capturing both the local and global features. Squeeze attention and convolution are used in parallel in the bottleneck to balance the extracted local and global features, while the Unified Attention between the encoder and decoder blocks improves critical feature learning. The model’s effectiveness is proven through training and testing on three publicly available datasets ISIC 2016, ISIC 2017, and ISIC 2018. Comparative analysis with state-of-the-art models indicates the suggested model’s remarkable performance, emphasizing its ability to delineate skin lesions precisely.
ICTDsC, 2024
Code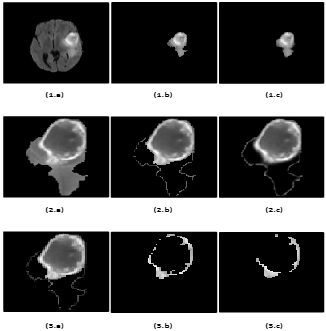
Automated Multi-Class Brain Glioma Segmentation Using 3-phase Cascaded mLinkNet with
Dense Concatenated Connections
(Accepted)
Abstract: Glioma, one of the most prevalent and aggressive brain tumors, can significantly reduce life expectancy. The potential of noninvasive magnetic resonance imaging (MRI) to help physicians diagnose, ... determine the extent of tumors, plan treatment, and manage disease was significant. However, automatic segmentation of brain gliomas from MR scanning remains a difficult, time-consuming and computationally intensive task. This paper presents an automatic technique for detecting brain tumor regions in multiclass brain MRI using a modified version of LinkNet (mLinkNet) based on convolutional neural networks (CNN). Three types of deep CNN models were trained: W-mLinkNet, C-mLinkNet and E-mLinkNet. The multiclass segmentation problem was solved by dividing it into three binary segmentation steps for glioma regions: whole tumor, tumor core, and growing tumor core, and the models were applied sequentially. In addition, we investigated zero-centering and intensity normalization as preprocessing steps to ensure uniform intensity variation in tissues. To demonstrate the effectiveness of the proposed CNN model, a comparative study was conducted using the Brain Tumor Segmentation Challenge 2015 database (BraTS 2015).
ICTDsC, 2024
Source will be made available
GRESIDAN: Graphically RESIDual Attentive Network For Tackling Aerial Image
(Under Review)Abstract: Deep learning has had rapid advancements, and new applications are developing in tasks like object detection and text recognition or occlusion handling, etc. Still, ... there are challenges because of the detection of objects in complex environments such as aerial images where things like motion blur, low light, and significant occlusion occur. This paper addresses the same challenges by introducing a novel framework, the Graphically Residual Attentive Network (GRESIDAN), which integrates three synergistic pipelines for object detection, occlusion detection, and occlusion removal. GRESIDAN uses a residually attentive block combining ResNet-18 and a multi-headed attention mechanism to improve feature extraction and detection accuracy in low-quality, occluded aerial images. A graphically attentive occlusion detection pipeline is implemented to handle occlusion, segment better, and mask out the occluder in the aerial image. The pipelines of the GRESIDAN model are validated on the COCO-2017 dataset and a custom private aerial object detection dataset, outperforming the state-of-the-art methods in handling occlusion and detecting objects. Our contributions provide a robust solution to the problem of detecting and handling occluded objects in aerial imagery, pushing the boundaries of automated visual recognition in challenging real-world scenarios.
Journal of Computers and Electrical Engineering
Code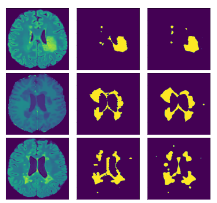
An attention based hybrid CNN module for efficient segmentation of
Multiple Sclerosis lesions
(Accepted)
Abstract: Multiple Sclerosis has been proven as a disease to potentially attack the Central Nervous System and render the patient disable in most cases. In light of medical advancements, it ... has been observed that the worst can be prevented, if the disease can be detected in the early stages and proper measures can be adapted. In spite of the great progress of the medical field, manual detection of Multiple Sclerosis Lesions still remains an uphill battle, owing to the requirement of meticulous expertise and longer time periods. Being privy to the recent success rate of convolutional neural network-based architecture in the Biomedical Field, we intend to leverage its competence towards the detection and segmentation of Multiple Sclerosis Lesions in the brain using Magnetic Resonance Images (MRI) scans of the same at our disposal. \textcolor{blue}{In this work, we propose a compound segmentation model which overcomes the pitfalls of a stand-alone backbone network utilising the representations generated by two different U-net based blocks and removing the block-wise redundancies through the synthesis of the compound representations. There are several other challenging discrepancies posed by the problem. The scarcity of data as the source and the huge imbalance between the number of lesion class and non-lesion class voxels.} The imbalance factor makes it strenuous for the model to learn the actual lesion classes, which is crucial to the aim of this work. To solve the challenge faced we have made use of specialized loss functions, which are designed to deal with such imbalance scenarios. In order to establish our model’s performance, we have validated on a patient-wise basis, using 3-fold cross-validation. We have used a plethora of evaluation metrics including Sensitivity, Precision, Dice Coefficient, MHD, and ASD, to ensure the proper monitoring of the model capabilities.
Journal of Multimedia Tools and Applications
Paper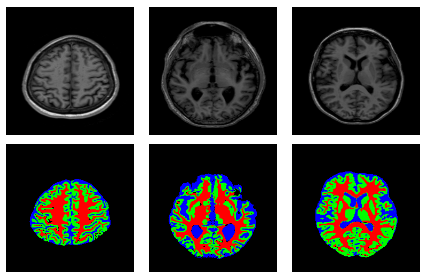
An Enhanced Deep Neural Network for Automatic Classification of Alzheimer’s Disease.
(Under preparation)Abstract: Alzheimer's disease is quite possibly the most deadly progressive neurodegenerative disease that weakens memory and psychological judgment. It is crucial to identify the early signs ... of the disease to aid the timely and effective treatment of the patient. A deep-learning framework is proposed which uses Convolution Neural Networks to build a combination of segmentation and classification methods. The architecture consists of a two-way training pipeline. The first path segments 2D MR image samples into Cerebrospinal Fluid, Gray Matter, White Matter (CSF, GM, WM), and is trained using the MRBrain18 and MRBrain13 dataset. The second path performs classification on the first path’s segmentation output using 3D convolutions and classifies the input data into three classes - Cognitively Normal, Mild Cognitive Impairment, and Alzheimer’s Disease (CN, MCI, AD). It is trained using the Alzheimer’s Disease Neuroimaging Initiative (ADNI) dataset. The proposed model achieves a promising performance on the multi-class classification (CN vs. MCI vs. AD) of Alzheimer’s Disease, yielding 89.2\% accuracy. An accuracy of 84.3\% is obtained when tested on a private curated dataset which exhibits the model's generalizability. The automated pipeline is built for an effective, rapid, and non-invasive assessment of AD, and hopefully, it helps ease the burden on physicians.